Inleiding
Met behulp van de module
Profit-Transact is het mogelijk om de Profit Database te repliceren naar een SQL Server Database. De module ontleent zijn naam aan de opzet waarbij iedere mutatie op een Profit tabel leidt tot een
Transaktie. Bij het verwerken van die Transakties (door een Replikatie Server) wordt de inhoud van dat record bijgewerkt in de SQL Server Database, zodat aldaar een kopie ontstaat van de tabel uit Profit.
Omstreeks 1994 is de eerste hand aan deze module gelegd, met hierbij tal van ideeën, welke nooit allen volledig zijn uitgewerkt danwel operationeel zijn geworden. Bedenk dat als een werkstation een record in een tabel muteert, we weten welke waarden er in dat record staan. Als vervolgens de Replikatie Server het record nogmaals bezoekt, kan vervolgens worden bepaald "wat" er gewijzigd is, en natuurlijk ook "door wie" en "wanneer", met daarmee de potentie om van ieder veld in Profit te kunnen achterhalen door wie ze wanneer is aangepast. Nog krachtiger is het als je bedenkt dat dat je op enig moment terug zou moeten naar de backup van de vorige dag, en je vervolgens "alle Transakties van de huidige dag" daar weer op los zou kunnen laten, om zodoende weer bij te zijn.
Hoewel de funktionaliteit hier nog steeds de potentie voor bevat, zijn de ideeën nooit echt uitgewerkt.
Januari 2019 is nu wel een begin gemaakt met het eerste deel: Profit bewaart nu (voor alle Transaktionele Tabellen) wie wat wanneer heeft gewijzigd. Daarmee is weer een basis gelegd voor diverse nog te ontwikkelen rapportages en funktionaliteit.
Replikatie wordt in praktijk toegepast om data te repliceren naar een SQL Server Database. Deze mogelijkheid bood Profit al in het DOS tijdperk, met daarbij de mogelijkheid om naast de Profit database ook over de volledige Database in een SQL Server te kunnen beschikken, welke (redundante) dataset weer gebruikt kan worden in bijv. het maken van een webshop. Gebruikers van de webshop zitten dan nooit in de échte Profit database, maar een kopie er van. Ook wordt de naar SQL Server gerepliceerde database gebruikt voor diverse eigen SQL tools en queries; iets wat op de VFP database niet echt mogelijk is.
Advantage Database serverSinds de introduktie van ADS is de noodzaak van het repliceren naar een separate SQL Server Database een stuk minder, immers, de ADS Database kan gewoon via SQL commando's worden benaderd en biedt ook funktionaliteit m.b.t. beveiliging en rechten. Eigen SQL Queries kunnen in principe rechtstreeks op de ADS Database worden losgelaten. Voor klanten die al sinds jaar en dag repliceren naar een SQL Server mag gelden dat er in het hele bedrijf al duizenden van dit soort Queries rondzwerven, en om die niet alleen aan te hoeven passen, kunnen we ook vanuit de ADS versie repliceren naar een separate SQL Server.
Repliceren tegenwoordig alleen nog vanuit ADS versieSterker nog... waar de vorige alinea beschrijft dat repliceren vanuit ADS eigenlijk niet meer nodig is, omdat die database gewoon al via SQL benaderd kán worden, geldt dat de regel nu is dat er alléén nog maar vanuit de ADS versie gerepliceerd kan worden. Repliceren vanuit de normale (VFP) versie is niet meer mogelijk. De reden hiervoor heeft te maken met het feit dat de oude opzet gebruik maakte van tools die ontwikkeld zijn in een toepassing die niet meer ondersteund wordt door hedendaagse 64 bits computers. Aangezien de klanten die naar een SQL Server repliceren allen over zijn naar ADS, is er voor gekozen dit niet voor VFP, maar binnen ADS opnieuw op te zetten, daarbij ook gebruik makend van bijv. de Auto Increment velden die ADS ons biedt.
Hoe zetten we e.e.a. op?
Allereerst hebben we een Server (PC) nodig waarop (Microsoft) SQL Server is geïnstalleerd.
Zo'n SQL Server installatie heeft een naam, bijvoorbeeld SS01 (SS01 = SQL Server 01). In dit topic is de naam van onze SQL Server
WS05\SQLWS05ADS.
Voordat we verder gaan, moeten we nadenken hoe we de Database op deze SQL Server willen aanmaken. Gegroeid vanuit het verleden zijn hier inmiddels 4 methoden voor, met daar weer een aantal varianten op. De laatste methode (#4) is degene het laatst ontwikkeld is, en tevens degene die nu als beste default optie geldt.
Methode 1 : één SQL Server, waarbij alleen vanuit de Produktiebestanden wordt gerepliceerd.Betreft feitelijk de eerst ontwikkelde methode. De Profittabellen staan op disk onderverdeeld in een 5 tal directory's voor zgn. Sub-Applikaties (LO, AD, PK, NT en SY). Bij de allereerst opzet van het repliceren is er voor gekozen om niet gewoon één, maar om 5 Databases aan te maken op de SQL Server; één Database voor ieder van de subdirectory's zoals deze op disk staan. De LO tabellen staan in Database LO, de AD tabellen in Database AD etc. Bij deze methode wordt er alleen data vanuit de Produktiebestanden gerepliceerd.
Methode 2 : één SQL Server, maar met Databases die uniek zijn gemaakt voor Test- en ProduktiebestandenEnkele jaren later ontstond ook de wens om vanuit de Testomgeving te kunnen repliceren. Net als dat in Profit de alle Tabellen uniek worden gemaakt naar een "TF" (TestFiles) en "PF" (ProductionFiles) directory, gebeurt dit vanaf methode #2 ook in de SQL Server Database. In plaats van 5 Databases worden er bij deze methode 10 aangemaakt: LOTF/LOPF, ADTF/ADPF, PKTF/PKPF, NTTF/NTPF en SYTF/SYPF.
Met deze methode kunnen we zowel de Data uit de Testbestanden alsmede de data uit de Produktiebestanden repliceren naar dezelfde SQL Server (SS01).
Methode 3 : Test- en Produktie repliceren ieder naar hun eigen SQL ServerNovember 2018 is er een 3e methode toegevoegd. Hierbij kan de data uit de Testbestanden naar een andere SQL Server worden gerepliceerd dan de data die uit de Produktiebestanden afkomstig is. Deze methode is ontwikkeld voor een klant wiens SQL Server database al was ingericht conform methode #1. Hun SQL Server Database was daarmee ingericht naar LO, AD, PK, NT en SY en daarmee kon er alleen vanuit de Produktiebestanden worden gerepliceerd. Zou die methode worden omgezet naar methode #2, dan kon er op zich gewoon ook vanuit Test worden gerepliceerd, maar... ook hier gold dat er duizenden gebruikers Query's in het hele bedrijf rondzwerfden waarbij (los van de Connectionstring naar de SQL Server) deze Queries allemaal zouden moeten worden aangepast m.b.t. de naamgeving van de te gebruiken SQL Server Database; LO zou ineens LOTF of LOPF moeten gaan worden. En, als dat gebeurd was, gold dat één Query weer niet uitwisselbaar was met de andere bestandenset, zonder eerst de LOPF verwijzigingen weer naar LOTF te veranderen.
Bij methode #3 kan nu voor Test- en Produktie een eigen SQL Server worden gekoppeld. Zo kunnen we instellen dat de LO Data in Test naar SS01\LO moet worden gerepliceerd en vanuit van Produktiebestanden naar SS02\LO.
Methode 4 : 1 SQL Database per ADS Data DictionaryFebruari 2019 is er een nieuwe methode toegevoegd, eentje die nu gewoon altijd zou moeten worden gebruikt. Sinds de introduktie van ADS geldt dat we nog maar twee Data Dictionaries hebben: 1 voor de Testbestanden (HP_TEST.ADD) en 1 voor de Produktiebestanden (HP_PROD.ADD). Zo'n Data Dictionary omvat daarna alle bestanden van LO, AD, PK, NT en SY die als 'set' bij elkaar horen. Doordat een AD tabel in dezelfde Data Dictionary zit als een LO tabel, zijn we daardoor ook eenvoudig in staat om een SELECT in een LO tabel uit te voeren, en een JOIN met een AD tabel op te nemen; iets wat voorheen lastiger was, immers, de AD Tabellen stonden formeel in een andere Database.
Bij methode 4 hebben we één SQL Server Database per ADS Data Dictionary. De naam van deze SQL Server Database is een afgeleide van de Directory waarin de ADS data wordt opgeslagen. Een voorbeeld lokatie van de ADS Database uit de Testbestanden zou kunnen zijn
\\ADS_DATA_SHARE\LIVE0001\HP_TEST.ADD. De laatste directorynaam in dat Path (LIVE0001) zal de naam worden van de SQL Server Database.
Sinds juli 2019 is deze methode 4 nog weer gekombineerd met de Systeemparameter waarmee we kunnen aangeven dat Test- en Produktie repliceren naar hun eigen SQL Server. Indien die parameter geaktiveerd is, zullen we de naam van de SQL Server Database voor zowel Test- alsmede voor Produktie gelijk maken aan deze directory. Vanuit de Testbestanden repliceren we dus naar een LIVE0001 database, en dat doen we ook vanuit de Produktiebestanden. Maar... let op: uitgangspunt is dus dat Test naar een andere SQL Server verwijst dan Produktie, dus, feitelijk repliceren we vanuit de Testomgeving naar bijv.
SS01\LIVE0001 en vanuit de Produktiebestanden naar
SS02\LIVE0001.
Als we géén separate SQL Server hebben voor Test- en Produktie (immers, het zou weer een extra SQL Server + licentie vergen) kunnen we die parameter ook uit laten staan. In dat geval zal de naam van de SQL Server Database uniek worden gemaakt naar Test- of Produktie data. Beide repliceren dan naar dezelfde SQL Server (SS01), maar vanuit Test repliceren we naar
SS01\LIVE0001_TEST en vanuit Produktie repliceren we naar
SS01\LIVE0001_PROD.
Om het nog wat complexer te maken
Stel dat we in plaats van één ADS Server (ADS01) over twee ADS Servers (ADS01 én ADS02) beschikken, dan kunnen we die formeel naar 4 SQL Servers laten repliceren. Hoe complexer we het maken, des te belangrijker wordt het om vanaf het begin af aan voor een goede naamgeving te zorgen, opdat voor iedereen duidelijk blijft welke database waarvoor gebruikt wordt. Zouden we dit vanaf het begin af aan opnieuw mogen opzetten voor 2 ADS Servers met 4 SQL Servers, dan zouden we kunnen kiezen voor een opzet:
ADS Server ADS01 repliceert v.w.b. de Produktiebestanden (HP_PROD.ADD) naar SS01\LIVE0001
ADS Server ADS01 repliceert v.w.b. de Testbestanden (HP_TEST.ADD) naar SS02\LIVE0001
ADS Server ADS02 repliceert v.w.b. de Produktiebestanden (HP_PROD.ADD) naar SS03\LIVE0001
ADS Server ADS02 repliceert v.w.b. de Testbestanden (HP_TEST.ADD) naar SS04\LIVE0001
Connection maken met SQL Server
Vanaf hier geldt dat mijn SQL Server de naam WS05\SQLWS05ADS heeft, in plaats daarvan zou u een van de hierboven genoemde namen moeten lezen.
In Microsoft SQL Server Management Studio geeft de Object Explorer deze SQL Servername weer; deze bevat (voor andere doeleinden in Profit) op dit moment al een andere Database (SDDATA). Deze SQL Servernaam gaan we nu ook gebruiken om vanuit Profit te kunnen repliceren.
Allereerst zullen we hiertoe vanuit Profit moeten verbinden met deze SQL Server. Er wordt dan a.h.w. een connection gemaakt vanuit Profit naar de specifieke SQL Server, en via die connection kan Profit data uitwisselen met die SQL Server.
De gegevens die nodig zijn om te kunnen verbinden zijn:
* Naam van de SQL Server (WS05\SQLWS05ADS)
* Loginname
* Password
Tot december 2018 gold dat
ieder werkstation een connection met de SQL Server Database
moest hebben, om bij het muteren van een record uit de Profit Database "de oude waarden" te kunnen bepalen. De Replikatie Server bezocht het record dan voor een tweede maal, en door te vergelijken wat er in het record stond, en wat er nu in staat, kon worden bepaald wat er was gewijzigd. Sinds december 2018 geldt dat de veldwaarden van dit "voor-" en "na-" bezoekje aan het record in de ADS Database worden geregistreerd. Hierdoor hoeven de separate werkstations géén verbinding meer te hebben met de SQL Server; alleen die werkstations die daadwerkelijk iets met de SQL Server Database doen. Dit zijn:
- de Replikatie Server, die de Transakties repliceert naar de SQL Server Database
- het werkstation waarop Upgrades worden uitgevoerd (indien we daarop ook de SQL Server Database willen aanpassen)
- eventueel een werkstation van de Systeembeheerder, voor als we Tabellen transaktioneel willen maken, of Resetmutatiebestanden willen doen
Op deze werkstations dienen daartoe een aantal regels te worden toegevoegd aan de Configuratiefile
CONFIG.HRT.
Voor methode #1 en #2 (zie eerder in dit topic) geldt dat we met één SQL Server werken, welke òf alleen repliceert vanuit de Produktiebestanden òf dit vanuit beide bestandensets doet. Door de volgende 4 regels op te nemen in de CONFIG.HRT maken we onszelf bekend aan de SQL Server.
Als we Test- en Produktiebestanden naar een andere SQL Server laten verwijzen (methode #3 en #4), dan zullen we eerst in de Systeemparameters (Hoofdmenu-9-3-1-1) moeten aangeven dat we voor Test- en Produktie gescheiden SQL Servers inzetten.
Profit zal niet (altijd) kunnen kontroleren of dit daadwerkelijk gebeurt, maar anticipeert er op dat als de parameter is ingesteld, dit door de systeembeheerder juist wordt ingericht!Als die parameter is op "Ja" is geset, kijken we bij het opstarten van Profit niet meer naar SQL Parameters van methode #1 en #2, maar gaan we op zoek naar een nieuw setje SQL Variabelen, die uniek zijn gemaakt naar de Test- danwel Produktiebestanden:
Voor de Testbestanden:
SQL_TEST_SERVER=ON
SQL_TEST_SRV=<SQL Server>
SQL_TEST_UID=<Userid>
SQL_TEST_PWD=<Password>
Voor de Produktiebestanden:
SQL_PROD_SERVER=ON
SQL_PROD_SRV=<SQL Server>
SQL_PROD_UID=<Userid>
SQL_PROD_PWD=<Password>
Als deze settings (in principe dus alleen nodig voor het werkstation waarop de Replikatie Server draait, danwel op het werkstation waarop een Upgrade wordt uitgevoerd, of die van de Systeembeheerder) zijn aangebracht, en Profit opnieuw wordt opgestart, kunnen we via Parameters Werkstation (Hoofdmenu-9-3-1-3) kontroleren of de juiste SQL Server gekoppeld is.
Let op:Ondanks dat (normale) Profit Gebruikers voor de Replikatie funktionaliteit
géén verbinding hoeven te hebben met een SQL Server, zal, zodra er met een SQL Server wordt gewerkt, dit tóch kenbaar moeten worden gemaakt in de Netwerk-Configuratiefile (
NCONFIG.HRT).
De opname van een regel:
SQLSERVER=OFF danwel, i.g.v. 2 SQL Servers:
SQL_TEST_SERVER=OFF én
SQL_PROD_SERVER=OFFis daarvoor voldoende. We geven hiermee aan dat er wél een SQL Server aan de orde is, maar dat het werkstation er geen verbinding mee hoeft te maken. Deze wetenschap is nodig omdat er een aantal Funkties zijn (zoals 'Resetmutatiebestanden' of 'Kopieren Produktie- naar Test') die absoluut niet mogen worden uitgevoerd op een 'normaal' werkstation zónder verbinding met de SQL Server. Zouden we dit wel toestaan, dan loopt de Profit Database direkt niet meer Synchroon met de SQL Server Database, en zijn we verplicht daarna de
hele database opnieuw te uploaden naar de SQL Server.
Let op: Als er geen SQL Server aan de orde is mogen de SQL (TEST-/PROD) SERVER regels in zijn geheel niet aanwezig zijn in de (N)CONFIG.HRT configuratiefiles!
Aanmaken SQL Server Database
Nu we een verbinding hebben gemaakt met de SQL Server, zullen we de Databases moeten aanmaken die Profit nodig heeft op deze SQL Server. Het aanmaken van een nieuwe SQL Server Database doen we vanuit Hoofdmenu-9-5-8-2-1 (Kreëren SQL DBMS). Aangezien tegenwoordig methode #4 de beste optie is, staat het scherm default zo ingevuld dat die methode getriggerd wordt.
Let op: Alvorens direkt op F1 te drukken, moeten we wel de (eerder genoemde) Systeemparameter waarmee we aangeven dat Test- en Produktie ieder een separate SQL Server aanstuurt geset hebben, immers, die setting is bepalend voor de naam van de SQL Server Database.
Als we één SQL Server hebben per bestandenset, zal de naam van de SQL Server Database
LIVE0001 worden. Hebben we géén separate SQL Server per bestandenset, dan zal de naam van de SQL Server Database een naam
LIVE0001_TEST danwel
LIVE0001_PROD krijgen. In beide gevallen moeten we overigens pér bestandenset een keer een SQL Server Database aanmaken. Na F1 worden alle ADS Tabellen opgenomen in de aangemaakte SQL Server Database. Aangezien deze handleiding een aantal keer is aangepast, bevat onderstaande schermprint een Databasenaam
DATA0001 i.p.v.
LIVE0001. Ofwel, waar in dit schermprintje DATA0001_TEST staat, zou bij het LIVE0001 voorbeeld er LIVE0001_TEST hebben gestaan.
Voor methode #3 vullen we het scherm als volgt in:
Per Applikatiekode krijgen we nu een aparte Database in de SQL Server, maar, deze wordt niet uniek gemaakt naar xxTF/xxPF, omdat we vanuit de Testbestanden zullen repliceren naar een andere SQL Server dan vanuit de Produktiebestanden. Op de SQL Server krijgen we nu per Applikatiekode een separate Database, ieder gevuld met de tabellen van die betreffende Applikatiekode:
Methode #2 triggeren we als we een vinkje plaatsen bij "SQL Server Database scheiden naar xxTF/xxPF". Op één SQL Server worden dan Databases aangemaakt om vanuit Test- en Produktie te kunnen repliceren.
Op de SQL Server worden de databases nu uniek gemaakt naar Test- en Produktiebestanden; we krijgen dus een setje xxTF en een setje xxPF bestanden. Overigens genereert 1x een aanroep van het kreëeren van een SQL DBMS maar één bestandenset; m.a.w. om zowel xxTF als xxPF te krijgen zullen we dit een keer moeten genereren vanuit de Testbestanden én een keer vanuit de Produktiebestanden. Daarna ziet het er uit als:
Methode #1 gaat op dezelfde wijze als methode #3, hooguit kunnen we i.g.v. methode #1 dit maar 1x doen, nl. alleen vanuit de Produktiebestanden. Vanuit de Testbestanden is dan geen replikatie mogelijk.
Op de SQL Server krijgen we nu per Applikatiekode een separate Database, ieder gevuld met de tabellen van die betreffende Applikatiekode:
Bij het aanmaken van een nieuwe SQL Server Database, worden ook direkt de
Collation en
Default Constraints aangebracht; de
Indexen worden echter nog niet direkt aangebracht. Dit, omdat de eerst volgende stap 'de Upload van data' zal zijn, en dit sneller gaat als niet direkt alle indexen bijgewerkt hoeven te worden.
Nb: Om technische redenen wordt tabel
LOAD niet gerepliceerd naar SQL Server; Tabelnaam "LOAD" betreft een Reserved Word in SQL Server. Mocht dit nodig zijn, dan zijn er altijd oplossingen te vinden in bijv. het repliceren van die tabel onder een andere naam, bijv. "XXAD".
Transakties Aan-/Uitschakelen voor Aktieve Bedrijf
Binnen Profit kunnen we de administratie voor meerdere bedrijven voeren. U bepaalt zélf welke van deze administraties moeten worden gerepliceerd naar de SQL Server Database. Als het wenselijk is dat
alle data naar de SQL Server repliceerd wordt (u wilt bijv. een kopie van de database op de SQL Server hebben) zult u ervoor moeten zorgen dat het Transaktie mechanisme in ieder bedrijf aktief is. Het kan ook zijn dat u uw SQL Server Database enkel gebruikt voor bijv. een koppeling met een Webshop, en waarbij in de SQL Database enkel de gegevens uit één (of desnoods een aantal, maar niet alle) bedrijf nodig is. Via Hoofdmenu-9-5-7-1 kunnen we van het Aktieve Bedrijf inzien of er vanuit die administratie gerepliceerd moet worden of niet; ook kunnen we via die Funktie de replikatiestatus wijzigen van AAN naar UIT (en andersom). De voornaamste reden van het kunnen uitschakelen van Transakties uit een bepaalde administratie betreft de performance; stel dat 2/3 van de records uit iedere Tabel niet naar de SQL Server hoeven, dan zal een initiële upload sneller gaan (immers die hoeft dan maar 1/3e te uploaden) en tevens zal het aantal te verwerken Transakties worden beperkt tot 1/3 (bij een gelijk aantal mutaties in alle administraties).
Upload Filters SQL Server Database
Voor het volgende onderdeel is het eigenlijk nog iets te vroeg, maar, ze is hier ingevoegd, opdat dit wel éérst wordt ingesteld alvorens u verderop uw data gaat uploaden naar de SQL Server database.
In een vorig hoofdstuk is uitgelegd dat we per bedrijf kunnen instellen of dat bedrijf Transaktioneel is of niet; dit omdat niet van alle administraties de data naar de SQL Server gerepliceerd hoeft te worden. Van de bedrijven die wél Transaktioneel zijn, is het mogelijk een aantal filters in te stellen die de hoeveelheid te uploaden records beperkt. Bij de meeste Profit implementaties bevat de database een historie van vele jaren, soms al méér dan 20 jaar. Ook hier moeten (nee, netter "kunnen") we een keuze gaan maken of het wel echt noodzakelijk is dat ál die informatie geupload moet worden naar de SQL Server Database. Als het antwoord op die vraag "Ja" is, dan stellen we simpelweg géén filters in. Is het echter niet nodig om alle data naar de SQL Server Database te uploaden, simpelweg omdat de Queries die op dié database worden losgelaten hooguit over het afgelopen jaar, of de afgelopen paar jaar gaan, dan is het mogelijk om de hoeveelheid te uploaden data te beperken met het instellen van een aantal filters.
Vanuit het Parameter Menu (Hoofdmenu, F5, F5) vinden we middels optie "T" een aantal van deze Upload Filters:
De hier opgenomen filters zijn bepaald op basis van voorkomende praktijk situaties. Situaties waarin er écht iets aan upload tijd te winnen valt als er een filter wordt ingezet. Dit zal dus vnl. aan de orde zijn zodra specifieke tabellen miljoenen records aan historische data bevatten. Dit soort filters zijn ook alleen maar aan de orde in zogenaamde
Mutatiebestanden en nooit in
Stambestanden (zoals bijv. een Artikelbestand of tabellen als Relaties en Debiteuren). Het aantal filters is hierbij ook niet uitputtend, het is best mogelijk dat uw specifieke situatie extra filters vereist, die kunnen we dan in dit scherm er bij maken.
Filters proberen we zo veel mogelijk 'algemeen' te houden, kunnen van invloed zijn op meerdere tabellen. Neem als voorbeeld het filter op Verkoopordernummer. Die zal niet alleen zijn effekt hebben op de Verkooporder Tabel (LOVO), maar ook op Verkooporderregels (LOVR), Raaplijsten (LOLL), Raaplijstregels (LOLR), Geleverde Charges (LOCL) en nog veel meer.
In sommige Tabellen worden ook meerdere filters tegelijk toegepast. Neem bijv. de Tabel met DKK Tarieven (LODF). Hierin vinden we de DKK Tarieven terug die als 'Stamgegevens' zijn vastgelegd, bijv. tarieven die op Artikelniveau, op Debiteurniveau, op Magazijnniveau etc. zijn vastgelegd, maar, deze tarieven worden vervolgens ook naar de Verkooporder (-/regel) of Inkooporder (-/regel) gekopieerd en kunnen daar op Order (-/regel) niveau weer worden gewijzigd. Voor zo'n tabel geldt dat het deel wat geldt als 'Stamgegevens'
altijd naar de SQL Server Database wordt geupload, maar dat de Tarieven op Verkooporder-/Inkooporder (of hun regelniveau) moeten voldoen aan de daarvoor opgegeven filters.
Merk op dat de filters op Ordernummer, op de Identifikatie van dat Ordernummer zijn afgestemd. U dient er zelf op te letten dat dit soort filters breed genoeg worden opgezet om datgeen wat u ermee wilt doen in uw SQL Server Database, er mee te kunnen doen. Met andere woorden, als we een filter leggen op de orders vanaf 20170000000, dan zullen alleen de orders die vanaf 1 januari 2017 zijn toegevoegd in de SQL Server Database worden opgenomen. Maar, misschien heeft u in december 2016 ook orders toegevoegd, die pas in 2017 moesten worden uitgeleverd, en in 2017 zijn gefaktureerd. Op die manier kunnen we op een Faktuur uit 2017 een order aantreffen uit 2016, en kan de SQL Sever Database de details van die order niet tonen omdat u met een filter heeft aangegeven dat de orders uit 2016 niet geupload hoeven te worden.
Misschien is dit helemaal geen probleem, en gaat het ook niet om de detail info. Toch moeten in dat geval uw SQL Query's hierop anticiperen, immers, als deze vanuit de Faktuurregels een INNER JOIN met een Orderregel bestand doen, wordt er niets gevonden, terwijl als u een LEFT JOIN doet, wordt de Faktuurregel wél gevonden, maar bevat de gejoinde orderregel NULL waarden.
De filter instellingen gelden per bedrijf! Dit is niet alleen om van de ene administratie aan te kunnen geven dat "alle data" naar de SQL Server geupload moet worden, en bij een andere administratie alleen "alles vanaf 2017", ook zijn filters per bedrijf noodzakelijk, omdat (al dan niet via Alternatieve Funkties) de opbouw van een ordernummer in sommige gevallen per bedrijf afwijkt; zo nummert de ene administratie haar orders als 2019.02.11.001 (puntjes even wegdenken) waar een andere administratie een extra positie in het volgnummer deel heeft ten koste van de eeuw, en nummert op een wijze 219.02.11.0001; één filter op ordernummer over alle bedrijven heen is daardoor niet mogelijk. Per bedrijf kunnen we nu in ieder geval doen wat we willen. Advies is dus alleen wel deze filters in te stellen alvórens we straks onze data gaan Uploaden naar de SQL Server Database, dat kan nl. een hoop upload tijd besparen.
ADStoSQL tool
Speciaal voor het uploaden van data van ADS naar SQL Server hebben wij een tool ADStoSQL.EXE ontwikkeld. Tussen de andere externe tools, waaronder het uploaden via een
Linked Server, hebben we niets gevonden wat werkt danwel op de door ons gewenste manier beïnvloedbaar is. De Linked Server was daarbij op zich ook een goede tool, ware het niet dat deze de geheugensettings van de SQL Server niet respekteert, en alleen maar geheugen in gebruik neemt en niet meer vrijgeeft, waarna de SQL Server uiteindelijk crasht.
Deze tool bevindt zich op de disk waarop ook de ADS Database staat. Met als uitgangspunt dat de locatie van onze ADS Data Dictionary
\\ADS01\ADS_DATA_SHARE\LIVE0001\HP_PROD.ADD is, is de locatie voor deze tools:
\\ADS01\ADS_DATA_SHARE\Tools\ADStoSQL\ADStoSQL.EXE.
De meest aktuele versie van deze tool kan worden gedownload
door hier te clicken.
ADStoSQL.EXE wordt vanuit Profit aangestuurt. Het uitvoeren van deze funktie vanaf een commandline is op zich zinloos, omdat Profit bepaalt wat die tool moet doen. Is ze daarmee klaar, dan sluit ze zich vanzelf af.
Transaktioneel maken Tabel in Profit
Waar een Profit implementatie uit meer dan 2500 verschillende tabellen bestaat, is het misschien helemaal niet nodig om al deze tabellen te repliceren naar de SQL Server. U bepaalt zelf welke tabellen wel/niet gerepliceerd moeten worden, door die tabellen al dan niet
Transaktioneel te maken. Strikt genomen kunnen we ook een niet-transaktionele tabel uploaden naar de SQL Server Database (omdat bij de Upload een vraag wordt gesteld of we alle tabellen òf alleen de Transaktionele Tabellen willen uploaden) maar, als deze Tabellen niet Transaktioneel zijn, zullen er géén Transakties worden gegenereerd uit Wijzigingen op deze Tabel. Een wijziging in Profit zal dus niet worden gerepliceerd naar de SQL Server Database.
Vanuit Hoofdmenu-9-5-7-3 kunnen we een Listmover overzicht opvragen van alle Tabellen in Profit met hun Transaktionele Status. Als eerste treffen we in dit scherm een Combobox (drop-down) control aan waarmee we kunnen filteren op de tabellen van een specifieke (sub-) Applikatiekode:
Na selektie van deze Applikatiekode worden de tabellen getoond die bij die Applikatiekode horen:
De linker lijst van deze Listmover control bevat de Tabellen die nog niet Transaktioneel zijn.
De rechter lijst van deze Listmover control toont de Tabellen die al wél Transaktioneel zijn.
Door een Tabel vanuit de Linker- naar de Rechter- lijst te verplaatsen, wordt de betreffende Tabel 'Transaktioneel' gemaakt. Transaktioneel betekent dat Profit van iedere wijziging in die Tabel een Transaktie maakt, die door de Replikatie PC wordt opgepakt. De Replikatie PC bepaalt vervolgens wat er wanneer en door wie gewijzigd is, en draagt zorg voor de replicering van deze wijzigingen naar de SQL Server Database. Alléén Tabellen die Transaktioneel zijn worden gerepliceerd naar de SQL Server database.
Het 'Transaktioneel zijn van een Tabel' kan ook weer worden opgeheven; hiertoe dient u de tabel uit de rechter lijst (Transaktioneel) te verplaatsen naar de linker lijst (niet transaktioneel).
Zodra een Tabel van de ene lijst naar de andere wordt verplaatst, gebeurt er op zich nog niets. De regel krijgt hooguit een status 'Pending' om aan te geven dat ze verplaatst is. Pas zodra er met F1 wordt verwerkt, zal de Tabel daadwerkelijk van Transaktionele Status worden gewijzigd. Zodra een Tabel kwa Transaktionele Status wordt gewijzigd, zal de Tabel opnieuw gereorganiseerd worden. Nadat de Tabel gereorganiseerd is 'weet' alle funktionaliteit in Profit dat haar Transaktionele Status is gewijzigd.
Nb:
- Een Tabel zónder index kan niet Transaktioneel worden gemaakt.
- Een Tabel die niet 'over is naar ADS' kan niet Transaktioneel worden gemaakt
Aanbrengen Auto Increment VeldIn een vorig hoofdstuk is beschreven dat
iedere ADS Tabel moet zijn voorzien van een Auto-Increment veld '_ADSAutoIncRecordId'. Dit veld is nodig om de records uit de ADS Tabellen uniek te kunnen idenficieren, iets wat een vereiste is voor het Replikatie proces. Aangezien we (via een Listmover tool) hebben 'toegestaan' dat de gebruiker zélf gefaseerd dit veld aanbrengt op de Database, kán de situatie zich voordoen dat het veld nog niet is aangebracht op de Tabel die we Transaktioneel willen maken. Derhalve zal, als de Transaktiestatus wordt gewijzigd van UIT naar AAN nógmaals worden gekontroleerd of de Tabel al over het Auto Increment veld beschikt, en zo niet, dan wordt dat veld alsnog on-the-fly aangebracht.
Uploaden van data van ADS naar de SQL Server DatabaseVanuit het menu "Systeembeheer - SQL Server" (Hoofdmenu-9-5-8-2) hebben we met optie #1 een SQL Server Database aangemaakt. Dit maakt op zich alleen de Database met zijn Tabellen aan, maar zorgt er nog niet voor dat die Tabellen gevuld zijn (noch worden er indexen opgebouwd). Om de ADS data te uploaden naar de SQL Server moeten we menu optie #3 gebruiken: "Migratie data naar SQL Server Database".
In de ultieme situatie zal een Tabel slechts 1x naar de SQL Server hoeven te worden geupload; daarna wordt de tabel bijgewerkt op basis van Transakties die door het Replikatie proces worden opgepakt. Toch kan het voorkomen dat een nieuwe upload om een andere reden benodigd is, omdat (om welke reden dan ook) de Tabel in de SQL Server Database niet meer synchroon loopt met de ADS Tabel.
Gewoon even een paar voorbeelden:
- Een Bedrijf, welke eerder niet Transaktioneel hoefde te zijn, is dat nu wel geworden
- Upload Filters zijn gewijzigd (ruimer gemaakt) waardoor data opnieuw geupload moet worden
- Netwerk problemen
- een fout in Profit
- òf zoals nu, konkreet, een totaal vernieuwde wijze van Replikatie, die vereist dat de database opnieuw wordt geupload
Het Uploaden van data van ADS naar de SQL Server gebeurt op twee plekken in Profit. Ten eerste met menu optie #3 uit bovenstaand menu, en ten tweede zodra we een (nieuwe) Tabel Transaktioneel maken (vanuit de eerder genoemde Listmover control). Als we op voorhand weten dat we
alle Tabellen opnieuw gaan uploaden naar de SQL Server, dan kunnen we het beste gebruik maken van menu optie #3. Indien we echter al enige tijd aan het repliceren zijn, en we besluiten om nóg een aantal Tabellen Transaktioneel te maken, dan is het handiger dat de aanvullende Tabellen die we Transaktioneel maken ook meteen geupload worden. Vanzelfsprekend zouden we ook kunnen stellen dat het Transaktioneel maken van een Tabel geheel los staat van de Upload, maar, met als uitgangspunt dat we bijv. 10 of 20 Tabellen Transaktioneel kunnen maken, zou het onzin zijn als we ná het Transaktioneel maken nogmaals die serie tabellen stuk voor stuk zouden moeten uploaden.
Toch ontstaat er nu ergens een soort discrepantie, immers, stel dat we nèt met repliceren gaan beginnen, en we nog geen enkele Profit Tabel Transaktioneel hebben gemaakt én een Tabel Transaktioneel moet zijn om te kunnen repliceren, dan zou het Transaktioneel maken van onze Tabellen deze al meteen doen uploaden, terwijl we juist gebruik willen maken van de massale upload die alle Tabellen tegelijk afhandelt. Een (en misschien zelfs duidelijkere) oplossing zou zijn dat we bij de Listmover control waarmee we een Tabel Transaktioneel maken de vraag stellen of die Funktie ook meteen moet zorgdragen voor de Upload J/N; dan heeft de Gebruiker feitelijk zelf de keuze.
In plaats daarvan is dit op een iets andere manier opgezet, gebruik makend van de wetenschap dat niet ieder werkstation een verbinding heeft met de SQL Server.
In een oudere versie van de Replikatie werd alle data die nodig is om te kunnen repliceren (bijv. de waarden van de velden uit de gemuteerde records) opgeslagen op de SQL Server zelf. Dit zorgde er voor dat iedere Gebruiker die een record wijzigde in Profit óók een connection met de SQL Server nodig had. In de nieuwe opzet wordt al dit soort data opgeslagen in de ADS Database. Dit zorgt er voor dat normale gebruikers niet hoeven te verbinden met de SQL Server. Alleen het werkstation waarop de Replikatie draait (en de PC waarop de Database Upgrade van de SQL Server Database wordt gedraaid, welke dezelfde mag zijn als de Replikatie PC) vereist een connection met de SQL Server. Op basis van de Transakties in Profit bepaalt ze wat er wanneer en door wie gewijzigd is, en bepaalt ze welke data er naar de SQL Server moet worden repliceerd.
Deze wetenschap wordt nu gebruikt om al dan niet de data direkt te uploaden vanuit het Transaktioneel maken van een Tabel: als een Tabel Transaktioneel wordt gemaakt op een werkstation welke géén toegang heeft tot de SQL Server, dan zal de tabel enkel Transaktioneel gemaakt worden (en wordt er géén data geupload). Wordt het Transaktioneel maken uitgevoerd op een werkstation die wel toegang heeft tot de SQL Server (bijvoorbeeld de Replikatie PC) dan zal dat proces ook direkt de tabel uploaden.
Upload FiltersAlvorens naar het daadwerkelijke Uploaden te gaan, maken we eerst een zijstapje naar Upload Filters. Deze zijn te vinden vanuit Hoofdmenu-9-5-7-2.
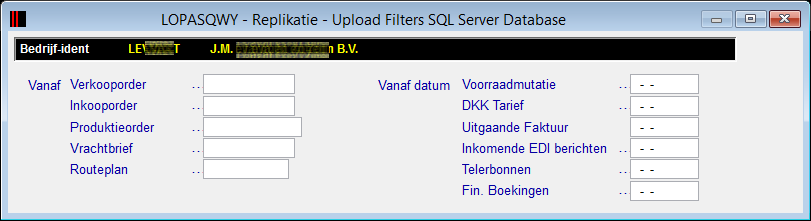
Met deze Upload Filters kunnen we een filter leggen op data niveau. Bedenk dat veel Profit gebruikers al minstens 10 of 20 jaar met Profit werken en deze data nog steeds direkt beschikbaar is in de Database. De vraag is nu of u deze data ook allemaal nodig heeft in de SQL Server Database. Het antwoord op die vraag zal ongetwijfeld afhangen van wat u met deze data die redundant in de SQL Server Database terecht komt wilt doen. Deze filter bieden op een aantal velden selekties. Stel dat u 100% zeker weet dat u met de Verkooporders vóór 2014 niets meer doet, en dat er ook géén orders meer open staan voor 2014, dan zou het filter op Verkooporder op "20140000000" kunnen worden gezet. Bij het Uploaden van de data van ADS naar SQL wordt dit Filter dan toegepast op een iedere tabel die een Verkoopordernummer bevat; Verkooporders, Verkooporderregels, Raaplijsten, Raaplijstregels, Charge-/Leveringen e.d.
Doel van zo'n filter is dus het beperken van de hoeveelheid te uploaden data; immers, als we maar 25% van de data hoeven te uploaden naar SQL Server, dan zal dit ook slechts een kwart van de benodigde tijd vergen. Voor alle filters geldt: ze worden pas gebruikt als er een waarde wordt ingevuld; laat u de rubriek leeg, dan zal het filter niet worden toegepast.
Nb: Merk op dat deze filters per Bedrijf instelbaar zijn. Dit zorgt ervoor dat u ervoor kunt kiezen om voor relatief kleinere administraties gewoon "alles" te uploaden naar SQL Server, maar voor grotere administraties met veel mutaties wél een filter wilt instellen.
Migratie data naar SQL Server DatabaseDan nu het daadwerkelijke uploaden van de data. Zoals gezegd doen we dat vanuit Hoofdmenu-9-5-8-2 met menuoptie #3.
Dit scherm biedt ons een aantal selekties waarmee we kunnen bepalen welke Tabellen er moeten worden geupload. Standaard staat het scherm zodanig ingevuld dat we alles wat nodig (transaktioneel) is, opnieuw gaan uploaden.
Het scherm biedt selekties op:
- Applikatiekode LO, AD, PK, NT of SY
- Tabelnaam van - t/m
- Inklusief "Mutatiebestanden J/N" (Nee doet alleen de "stambestanden")
- Alleen "Transaktionele Bestanden J/N" (Nee doet ook de Tabellen die niet Transaktioneel zijn, en dus verder niet via Transakties worden bijgewerkt)
Vervolgens toont het scherm welke Bedrijven binnen Profit "Transaktioneel" zijn gedefiniëerd; stel dat een SQL Server Database wordt ingezet voor een webshop, dan is het niet nodig om ook de data uit andere administraties te repliceren naar de SQL Server Database.
Tsja... verder spreekt het voor zich. We zullen de selekties in (of laten de default staan) en drukken op F1.
Als een Tabel opnieuw geupload wordt, dan
* worden alle nog niet verwerkte pending Transakties voor deze Tabel verwijderd
* wordt een eventueel bestaande Tabel in de SQL Server Database verwijderd (DROP TABLE)
* wordt er een nieuwe Tabel aangemaakt in de SQL Server Database (CREATE TABLE)
* wordt de data uit de ADS tabel overgeheveld naar de SQL Server Database
* worden de indexen op de Tabellen in de SQL Server Database opgebouwd
Tijdens de verwerking wordt op het scherm bijgehouden met welke taak het systeem bezig is:
Het uploaden zelf gebeurt via een speciaal voor deze taak ontwikkelde tool "ADStoSQL.EXE". Deze tool wordt door Profit op de achtergrond opgestart, pikt de Tabellen op waarvan Profit heeft bepaald dat ze geupload moeten worden en bepaalt op basis van de Transaktionele Bedrijven en de Upload tools welke records wel/niet moeten worden geupload. Zodra de tool klaar is met het Uploaden van de data, zal deze Tabel door Profit weer worden opgepakt om als laatste de Indexen aan te brengen op de Tabel.
De ADStoSQL tool heeft een eigen scherm waarin de voortgang van de upload wordt weergegeven:
In dit scherm kunnen we zien vanuit welke ADS Data Dictionary en naar welke SQL Server Database wordt gekopieerd, hoeveel Tabellen er verwerkt moeten worden, en hoeveel er daarvan al klaar zijn. Via een Progress Bar wordt zichtbaar gemaakt in hoeverre de upload gevorderd is.
Uploaden in meerdere doorlopenHoewel een massale upload normaliter in een weekend zal worden uitgevoerd en er geen Gebruikers in het systeem zullen zitten, anticipeert de upload er op dat e.e.a. ook in een noodsituatie geupload moet kunnen worden. In zo'n situatie zullen we dus zo snel mogelijk in Profit verder willen kunnen gaan. Als we iedere Tabel in één keer gaan uploaden, zou dat impliceren dat als we bij een Verkooporderregel tabel aankomen van 20 GB (en 20 jaar historie) we heel lang zitten te wachten op het uploaden van data waarvan toch al bekend is dat deze niet meer zal wijzigen. "Mutatiebestanden" (de bestanden die dagelijks steeds groter worden naar mate het aantal mutaties/orders toeneemt) worden derhalve in etappes geupload. Tevens geldt dat gedurende die meerdere etappes de Tabel van onderen naar boven wordt doorlopen; ofwel, de laatst toegevoegde records zullen als eerste naar de SQL Server worden overgeheveld (immers de nieuwste orders zullen eerder 'open staan' dan de eerste records in een tabel). "Stambestanden" (zoals een Artikelbestand) worden in principe altijd in 1x geupload.
Het aantal records wat bij een Mutatiebestand in één doorloop wordt geupload hangt af van de recordgrootte van die tabel. Hoeveel doorlopen er nodig zijn wordt niet berekend, wel tonen we met welke doorloop we bezig zijn (zie rubriek "Pass: 1").
PrioriteitAchter de schermen gebeurt er nog meer om zo snel mogelijk weer verder te kunnen in Profit. Zo bepaalt Profit op basis van prioriteiten in welke volgorde de Tabellen moeten worden geupload naar de SQL Server.
Transaktioneel boven niet-transaktioneelEen tabel die transaktioneel is, krijgt altijd voorrang boven een tabel die niet-transaktioneel is. Vanzelfsprekend is deze prioriteit alleen aan de orde als we ervoor kiezen om óók de niet transaktionele Tabellen te uploaden; ze komen echter pas aan de beurt nadat de wél-transaktionele tabellen geupload zijn.
Stambestand boven MutatiebestandStambestanden, zoals een Relatietabel of de Artikelgegevens krijgen tijdens het Uploaden van data voorrang boven Mutatiebestanden (zoals Verkooporders, Verkooporderregels etc.). Op deze manier hebben we deze Stamgegevens als eerste beschikbaar in de SQL Server Database.
Volgorde LO, AD, SY, PK, NTDe hierboven bepaalde kombinatie, worden de tabellen weer afgehandeld op volgorde van de Applikatiekode waartoe ze behoren. Logistieke Stambestanden hebben dus voorrang boven Financiële Stambestanden. PK en NT komen hierin als laatste aan de beurt; statistisch gezien worden deze Tabellen het minst gebruikt in de SQL Server Database.
Performance Query's op SQL ServerNieuw is ook dat Profit zelf indexen aanmaakt op de Tabellen in de SQL Server Database. Waar een SQL Query voorheen "op kracht" moest worden uitgevoerd, kan ze nu veelal gebruik maken van indexen, waardoor we sneller resultaat verkrijgen. De indexen die aangemaakt worden zijn in principe dezelfde indexen als die we in ADS aanmaken t.b.v. SQL Query's. Deze indexen worden per Tabel dynamisch bepaalt. Het zijn steeds indexen op slechts 1 veldnaam, getriggerd door de indexen die wij in Profit vanuit coding gebruiken. M.a.w., zodra we omwille van een overzicht in Profit een index op Tabel "Verkooporders" hebben geplaatst om snel "de openstaande Verkooporders" te kunnen vinden, dan zal er nu ook een SQL Index bestaan op deze Openstaand Indikator. Aangezien er ook een index is om de Verkooporders van een Debiteur te kunnen ophoesten, is er nu vanzelf ook een index op Debiteur. Feitelijk komt het erop neer dat als wij in Profit hebben bepaald dat er ergens een index nodig is t.b.v. performance issues, die zelfde indexen nu ook (maar dan op de separate indexvelden) worden aangemaakt op de Tabel in de SQL Server Database. Met name JOIN's zullen hierdoor sneller performen, immers, een JOIN vindt normaliter plaats op indexvelden, waardoor de JOIN nu altijd gebruik kan maken van de indexen die op de SQL Server Database zijn aangebracht.
Als alle Tabellen geupload zijn, verdwijnt het ADStoSQL scherm (en zal Profit zelf nog even door kunnen gaan met het reorganiseren van de Tabellen die door ADStoSQL zijn geupload).
FoutenHet kan ook voorkomen dat er (om welke reden dan ook) fouten worden gekonstateerd tijdens de Upload. Zodra we een fout konstateren, gaan we dat deel van de upload opnieuw proberen, maar dan met een kleinere selektie. Gaat het weer fout, dan wederom een poging met nog een kleinere selektie. Dat doen we tot maximaal 5 keer toe, en als het dan nog steeds fout gaat, wordt de upload van die tabel afgebroken. In een logfile (de naam er van staat ook in het scherm vermeld, maar, dit betreft een logfile die in de "temp" directory staat van de te uploaden ADS Data Dictionary) zal deze fout worden gerapporteerd. Via een text file kan worden achterhaald welke tabel(len) er fout zijn gelopen. Het totaal aantal fouten wordt geregistreerd onder het Label 'Error:'.
FoutenHet kan ook voorkomen dat er (om welke reden dan ook) fouten worden gekonstateerd tijdens de Upload. Zodra we een fout konstateren, gaan we dat deel van de upload opnieuw proberen, maar dan met een kleinere selektie. Gaat het weer fout, dan wederom een poging met nog een kleinere selektie. Dat doen we tot maximaal 5 keer toe, en als het dan nog steeds fout gaat, wordt de upload van die tabel afgebroken. In een logfile (de naam er van staat ook in het scherm vermeld, maar, dit betreft een logfile die in de "temp" directory staat van de te uploaden ADS Data Dictionary) zal deze fout worden gerapporteerd. Via een text file kan worden achterhaald welke tabel(len) er fout zijn gelopen. Het totaal aantal fouten wordt geregistreerd onder het Label 'Errors:'.
Repliceren Transakties
Indien SQL Server Database is aangemaakt, en de Tabellen zijn geupload naar deze SQL Server Database, dan zorgt het Replikatie proces er voor dat alle mutaties worden gerepliceerd naar de SQL Server. Deze Replikatie moet gedraaid worden op een werkstation welke (dedicated) bezig is met het repliceren van data naar de SQL Server. Dit werkstation moet (vanzelfsprekend) dus beschikken over een verbinding (rechten) op de SQL Server.
De replikatie starten we op vanuit Hoofdmenu-9-5-7-4. Daarna hoeven we enkel nog op 'Start' te clicken om het Replikatie proces te starten.
Zodra we in Profit records muteren in Tabellen die Transaktioneel zijn, zal dat leiden tot een Transaktie. De Replikatie PC verwerkt deze Transakties, gaat de gemuteerde records nogmaals bezoeken (maar alleen indien nodig), bepaalt wat er gewijzigd is, en schrijft de gemuteerde data weg naar de gekoppelde SQL Server Database. Het aantal records welke herbezocht is, waarvan de mutaties zijn bepaald, en welke repliceerd zijn, worden bijgehouden in een tellertje in het kader. In dat kader zien we tevens wat de huidige status is (Wacht op Transaktie) en bijv. hoe lang de Replikatie PC al staat te wachten (12 seconden).
In de ideaal situatie zal het er op neer komen dat als we 1.000 Transakties vinden, er ook 1.000 records herbezocht moeten worden, en er 1.000 records moeten worden aangemaakt (of gewijzigd) in de SQL Server Database. In het schermprintje zien we dat op diezelfde manier alle tellers op 11.788 staan. Toch hoeft het niet per definitie zo te zijn dat al deze tellers aan elkaar gelijk te zijn, dus, geen zorgen als dat eens niet het geval is :-)
Zo geldt bijv. dat de Replikatie PC niet noodzakelijk ieder record opnieuw hoeft te bezoeken. Zoiets kan bijvoorbeeld optreden indien het record inmiddels (desnoods door een andere Gebruiker) opnieuw gewijzigd is. Omdat we er naar streven de tellers toch zo veel mogelijk synchroon te laten lopen, zal in zo'n geval de 'herbezocht' teller toch worden verhoogd, ook al is het 'herbezoek' niet door de Replikatie PC uitgevoerd.
Dat een Transaktie wordt opgepakt door de Replikatie PC impliceert dat het record opnieuw beschreven is. Maar... de Replikatie PC gaat ook uitzoeken "wat" er precies gewijzigd is. Zo kan het voorkomen dat een record weliswaar is aangepast, maar beschreven is met dezelfde waarde. Zoiets kan voorkomen omdat niet iedere funktie kontroleert of alle velden gewijzigd zijn. Denk hierbij aan situaties waarbij als we een Verkooporderregel leveren, de status van de Verkooporder op "L" (Levering) moet komen te staan. Maar, als we nu 3 Verkooporderregels van dezelfde order leveren, zou de betreffende funktionaliteit in theorie 3x die status "L" kunnen wegschrijven (waar ze al een status "L" had). De Replikatie PC konstateert nu dat er weliswaar een record beschreven is, maar dat er feitelijk niets is veranderd, en er (dus) ook niets hoeft te worden gerepliceerd naar de SQL Server Database.
In de oude opzet van het Replikatie proces gold dat er "enkel" data werd gerepliceerd naar de SQL Server. In de nieuwe opzet gebeurt dat deel natuurlijk ook, maar, aanvullend bewaren we in de stappen daar naar toe ook precies wat er tijdens welke Transaktie werd gewijzigd. Op die manier moet van ieder veld in de database te achterhalen zijn door wie, en wanneer ze werd gewijzigd, en welke waarde het veld had vóórdat ze werd gewijzigd. De data is er... tools die er iets mee doen zijn op dit moment nog niet ontwikkeld (maar het mag duidelijk zijn dat deze informatie tal van nieuw te ontwikkelen funktionaliteit kan uitlokken).
Upgrade SQL Server Database
Zodra we een Upgrade uitvoeren in Profit wordt de struktuur van de Database gelijkgetrokken met de stand die bij die Upgrade hoort. Zo kan een Upgrade er toe leiden dat bestaande Tabellen kwa indeling worden gewijzigd, of dat er geheel nieuwe Tabellen worden toegevoegd aan de Database. In theorie kan het ook wel eens voorkomen dat er bestaande velden komen te vervallen. Hoe dan ook, iedere Upgrade kan leiden tot het aanpassen van de Database Struktuur. Aangezien we nu data repliceren naar een SQL Server, zal ook de Database Struktuur van de SQL Server Database moeten worden aangepast. Na
iedere Upgrade zal derhalve
expliciet een Database Upgrade van de SQL Server Database moeten worden uitgevoerd. Deze funktionaliteit vinden we via Hoofdmenu-9-5-8-2-2.
De Database Upgrade op de SQL Server draagt zorg voor:
- het gelijktrekken van de Database Struktuur met die van de Upgrade
- het aanbrengen van veranderingen in zowel de VFP alsmede SQL Indexen op de SQL Server Database
- nieuwe Tabellen worden automatisch voorzien van de Case Insensitive Collation
- gewijzigde Velden worden voorzien van de juiste defaultwaarden (Contraints)
Let op:De volgorde van de velden in de SQL Server Tabel is
niet (altijd) gelijk aan de volgorde van de velden in de ADS Tabel. Voor januari 2019 was dat nog wel het geval, maar, omwille van performance redenen zijn we hier vanaf gestapt! In Visual FoxPro is de volgorde van de velden in een tabel van wezenlijk belang. Zo zijn er commando's zoals SCATTER en GATHER die de inhoud van een record kunnen kopiëren zonder dat deze de 'wetenschap' hebben welke waarden voor welk veld bestemd zijn. Als we in ADS een veld in een bestaande tabel willen invoegen na een bepaald veld, dan biedt ADS die mogelijkheid. Hoewel het in MySQL wel mogelijk is om een veld in een SQL Tabel in te voegen op een bepaalde plek (ALTER TABLE LOAR ADD Testveld Char(20) AFTER LOAR_AID) is dit in SQL Server niet mogelijk! Tot op heden was de oplossing dan altijd dat we de oude tabel rename-den, vervolgens een nieuwe tabel gingen aanmaken, en vervolgens alle data uit de oude tabel overhevelden naar de nieuwe tabel. Hoewel deze methode technisch natuurlijk werkt, zal het kopiëren van de tabel vele malen meer tijd in beslag nemen dan indien we enkel het veld zouden hoeven op te nemen. Met name omdat we in ADS het AutoIncrementRecordId altijd achteraan in de database zullen willen houden, geldt dat 'invoegen' straks altijd aan de orde is, wat de performance van een Database Upgrade aanzienlijk zal beïnvloeden. Per heden is dan ook gesteld dat 'performance' belangrijker is dan 'de wenselijkheid de tabelstructuren gelijk te houden'.
Merk overigens op dat als we een SQL Server Tabel benaderen, we meestal alleen de velden ophalen die we nodig hebben; de volgorde waarin de velden in de SQL Database staan doet er dan niet toe. Dat de volgorde afwijkt zal wel zichtbaar zijn als we SELECT * FROM in een SQL Server Tabel doen.
Let op:In een omgeving waarbij de normale werkstations géén toegang hebben tot de SQL Server, maar de Replikatie PC wel, dient deze SQL Server Database Upgrade
altijd op deze Replikatie PC te worden uitgevoerd (immers, die kan verbinden met de Database op de SQL Server).
Reorganiseren Tabellen in SQL Server Database
Hoofdmenu-9-5-8-2-7 staat u toe om de (Profit) Tabellen die in de SQL Server Database staan opnieuw te reorganiseren. Tijdens deze Reorganisatie worden alle bestaande indexen van de Tabel uit de SQL Server Database verwijderd; daarna worden de indexen opnieuw aangemaakt conform de in Profit (ADS) bekende SQL Indexen; dit zijn indexen op alle separate sleutelvelden uit alle indexen die door Profit zelf gebruikt worden. Als we bijv. op een Verkooporderregel Tabel (LOVR) een index hebben op de velden LOSU_SID (Bedrijf) + LOVO_OID (Verkooporder) + LOVR_RNR (Verkooporderregel), dan zal die ene 'Profit index' leiden tot de opname van 3 SQL Indexen; één op veld LOSU_SID, één op veld LOVO_OID én één op veld LOVR_RNR.
Kopiëren Produktie- naar Test
Hoofdmenu-9-5-9-1-3 biedt een tool waarmee de Produktiebestanden van de ADS Database kunnen worden gekopiëerd naar de Testbestanden. Deze tool is ontwikkeld om de Testbestanden te kunnen voorzien van nieuwe 'live-data' om vervolgens met deze aktuele data te kunnen testen in de Testbestanden. Kopiëren Produktie- naar Test kopiëert echter enkel de ADS Database, maar
niet de SQL Server Database!
Dus, stel het voorbeeld dat we vanuit de Produktiebestanden repliceren naar een SQL Server SS10/PROFIT_PROD_PRIMARY en we vanuit de Testbestanden repliceren naar een SQL Server SS12/PROFIT_TEST, en we kopiëren Produktie- naar Test, dan is onze ADS Database weliswaar van Produktie- naar Test gekopieerd, maar daarmee is de inhoud van SS10/PROFIT_PROD_PRIMARY nog niet gekopiëerd naar SS12/PROFIT_TEST!
Vanzelfsprekend zou het het mooist zijn als we dit "met een druk op een knop" konden doen, maar dat is helaas niet het geval!
Met dat we Produktie- naar Test kopiëren is stand tussen de Testbestanden van Profit en SS12/PROFIT_TEST
per definitie niet meer consistent! Dit zou eigenlijk impliceren dat we zouden moeten blokkeren dat iemand deze funktionaliteit kan uitvoeren, ware het niet daar daardoor essentiële funktionaliteit verloren gaat, immers, kunnen testen met aktuele data uit de Produktiebestanden is iets wat vaak gebruikt wordt.
Derhalve staan we het kopiëren van Produktie- naar Test wél gewoon toe, maar zijn hierbij diverse meldingen ingebouwd die aangeven dat u er zélf voor moet zorgen dat ook de SQL Server Database gesynchroniseerd wordt, bijvoorbeeld door:
- na de kopiëerslag de (Transaktionele) Testbestanden opnieuw te uploaden naar de SQL Server Database
- zelf op e.o.a. manier de data van SS10/PROFIT_PROD_PRIMARY te kopiëren naar SS12/PROFIT_TEST (of door de SS10 te backupppen, en te restoren in SS12)
Reset Mutatiebestanden
Reset Mutatiebestanden betreft een tool die alle Mutatiebestanden doorloopt en de data v.w.b. het Aktieve Bedrijf hieruit verwijderd. De tools is oorspronkelijk voor Heart zelf ontwikkeld, waar wordt bij diverse klanten ook gebruikt. Ze helpt voorkomen dat we bij het testen "door de bomen het bos niet meer zien". Denk bijvoorbeeld aan het implementeren van een Behoefterun, waarbij e.e.a. al moeilijk genoeg is als iemand 'met een schone lei' begint en alleen de impact ziet van de situatie die hij op dat moment aan het testen is.
Als de Profit Database wordt gerepliceerd naar een SQL Server Database, dan geldt dat Reset Mutatiebestanden niet alleen de mutaties uit de Profit Database moet opschonen, maar ze zal óók de mutaties uit de SQL Server Database moeten verwijderen. Om 'Reset Mutatiebestanden' uit te kunnen voeren is er derhalve een verbinding nodig met de SQL Server Database; deze Connection zal rechten moeten hebben om iedere gerepliceerde tabel op de SQL Server te mogen aanpassen.
(Achteraf) Aanbrengen Case Sensitive Collation
Vanaf januari 2019 geldt dat de Collation al direkt wordt aangebracht bij het aanmaken van een nieuwe SQL Server Database. Via Hoofdmenu-9-5-8-2-5 kan de Collation altijd achteraf (nogmaals) worden toegekend; dit kan bijv. aan de orde zijn als uw SQL Server Database voor 2019 is gegenereerd, en nog niet voorzien is van de juiste Collation.
Vanuit Profit voorzien wij de SQL Server Database van een Collation genaamd
Latin1_General_CS_AS. De "CS" in deze Collation staat voor Case Sensitive. Het aanbrengen van een Case Sensitive Collation is van belang, omdat er in Profit ook gebruik wordt gemaakt van Case Sensitive Identifikaties; denk aan Artikelnummers of Chargenummers die kleine letters mogen bevatten, of Grootboekrekeningen, Kostenplaatsen en Kostensoorten die in dezelfde tabel ADGR staan, maar uniek worden gemaakt door het Rekeningschema te manipuleren.
(Achteraf) Aanbrengen DEFAULT Constraints
Ook de DEFAULT Contraints worden automatisch aan de SQL Server Database toegevoegd als deze ná januari 2019 wordt gegenereerd. Ook hier geldt dat het mogelijk is om achteraf (nogmaals) deze contraints op te nemen, nl. via Hoofdmenu-9-5-8-2-6.
Met deze DEFAULT Constraints voorzien we de SQL Server Database van zgn. Defaultwaarden. Het uitvoeren van deze run zorgt ervoor dat Charactervelden standaard met een spatie worden gevuld, Numerieke Velden default van de waarde 0 worden voorzien en Logicals op False komen te staan. Doel van het aanbrengen van deze defaultwaarden is om te voorkomen dat velden die niet gereplaced worden de waarde NULL toegekend krijgen. Formeel zal NULL staan voor 'niet ingevuld' en niet zo zeer voor 'leeg' of 'spaties', toch is dit voor veel SQL Queries niet handig, omdat als we op zoek zijn naar bijv. Voorraaditems waarvan het Interne Chargenummer niet gevuld is, we ineens dubbel moeten kontroleren (CHARGEIN = '' OR CHARGEIN IS NULL).
Een Datumveld is overigens het enige type veld welke wél standaard met een NULL value wordt gevuld, dit, omdat zowel VFP alsmede ADS formeel ook een waarde "leeg" kennen voor een datumveld. Hoewel een defaultdatum in SQL ook veelal 01-01-1900 betreft, klopt dat voor die situaties niet, en derhalve blijft het veld NULL als ze niet gevuld is.
Mogelijke uitbreidingen
Resteert nog een aantal opties, welke technisch best te realiseren zijn, welke niet in het oude ontwerp waren afgevangen, waar nu niet om gevraagd is, en waar we zonder opdracht nog even niet aan beginnen.
- Replikatie laten herkennen dat er een massale upload aktief is.
Het idee er achter is dat als dat er een massale upload is ingezet, de Replikatie PC op zich ook best aangezet zou kunnen worden. Deze zou dan Transakties op records die nog niet zijn geupload naar de SQL Server tijdelijk kunnen parkeren, en pas gaan verwerken zodra die records wél geupload zijn. 'Win-faktor' is dat Gebruikers sneller weer in Profit verder kunnen gaan met hun dagelijkse handelingen. - Funktionaliteit m.b.t. welke Tabellen / Sleutels gewijzigd zijn, wat er gewijzigd is, wanneer en door wie
- Transakties opnieuw repliceren vanaf een in te geven tijd
Te denken valt aan een situatie waarbij op de SQL Server een restore is gedaan van gisteren, en we alle Transakties die na gisteren zijn gemaakt, opnieuw willen repliceren naar de SQL Server - Reset Mutatiebestanden terwijl er een SQL Server aktief is

